


Wouldn’t it’s good to spend much less time on information engineering and extra on making the proper enterprise selections? We helped revamp the consumer’s system in a means that made it attainable for information scientists to have prompt entry to the corporate’s info. Because of this, they might get extra insights from it. How did we do it? The brief reply is by implementing an information lake. Need to know extra? Try the entire tech examine.
By skilfully implementing the information lake on AWS, we had been in a position to present fast, orderly, and common entry to an incredible wealth of information to the whole thing of the consumer’s group. Simply have a look!
On account of that change, the corporate’s inner group may create new sorts of charts and dashboards filled with distinctive insights that minimize proper by data silos that beforehand blocked this intelligence from being gathered collectively.
Cloud-based initiatives like this one are what we like to do at The Software program Home. We recommend having a look at our cloud growth and DevOps companies web page to study extra about our actual method, expertise, and expertise.
In the meantime, let’s take a step again and provides this story a extra correct clarification.
Background – fintech firm in the hunt for environment friendly information system
Probably the most prized traits of a seasoned developer is their means to decide on the optimum answer to a given downside from any variety of prospects. Making the proper alternative goes to impression each current and future operations on a enterprise and technical degree.
We received to display this means in a latest mission. Our consumer was occupied with boosting its enterprise capabilities. As the corporate was rising bigger and bigger, it turned more and more tough to scale its operations with out the correct data that it may solely achieve by deep and thorough evaluation. Sadly, at that cut-off date, they lacked the instruments and mechanisms to hold out such an evaluation.
One in all their greatest issues was that they had been getting an excessive amount of information, from many various sources. These included databases, spreadsheets, and common information unfold throughout numerous IT methods. In brief – tons of beneficial information and no good technique to profit from it.
And that’s the place The Software program Home is available in!
Challenges – selecting the best path towards wonderful enterprise intelligence
Selecting the correct answer for the job is the muse of success. In just about each mission, there are a number of core and extra necessities or limitations that devs have to take into accounts when making their determination. On this case, these necessities included:
- the flexibility to energy up enterprise Intelligence instruments,
- a technique to retailer giant quantities of knowledge,
- and the chance to carry out new sorts of evaluation on historic information, regardless of how previous it was.
There are numerous information methods that may assist us try this, specifically information lakes, information warehouses, and information lakehouses. Earlier than we get any additional, let’s brush up on concept.
Information lake vs information warehouse vs information lakehouse
A information lake shops all the structured and uncooked information, whereas a information warehouse accommodates processed information optimized for some particular use instances.
It follows that in an information lake the aim of the information is but to be decided whereas in an information warehouse it’s already recognized beforehand.
Because of this, information in an information lake is extremely accessible and simpler to replace in contrast to a knowledge warehouse wherein making modifications comes at the next worth.
There’s additionally a 3rd choice, a hybrid between an information lake and an information warehouse also known as a information lakehouse. It makes an attempt to combine one of the best components of the 2 approaches. Particularly, It permits for loading a subset of information from the information lake into the information warehouse on demand. Nevertheless, because of the complexity of information in some organizations, implementing it in apply could also be very pricey.
ETL or ELT?
One of many main considerations whereas engaged on such information methods is methods to implement the information pipeline. Most of us most likely heard in regards to the ETL (“extract, rework, load”) pipelines, the place information is extracted from some information sources at first, then remodeled into one thing extra helpful, and at last loaded into the vacation spot.
It is a excellent answer after we know precisely what to do with the information beforehand. Whereas this works for such instances, it doesn’t scale nicely if we wish to have the ability to do new sorts of evaluation on historic information.
The rationale for that’s easy – throughout information transformation, we lose a portion of the preliminary info as a result of we have no idea at that time whether or not it’ll be helpful sooner or later. Ultimately, even when we do have an excellent thought for a brand new evaluation, it could be already too late.
Right here comes the treatment – ELT (“extract, load, rework”) pipelines. The plain distinction is that the information loading section is simply earlier than the transformation section. It implies that we initially retailer that information in a uncooked, untransformed type and at last rework it into one thing helpful relying on the goal that’s going to make use of it.
If we select so as to add new sorts of locations sooner or later, we are able to nonetheless rework information in accordance with our wants on account of the truth that we nonetheless have the information in its preliminary type.
ETL processes are utilized by the information warehouses, whereas information lakes use ELT, making the latter a extra versatile alternative for the needs of enterprise intelligence.
The answer of alternative – information lake on AWS
Bearing in mind our striving for in-depth evaluation and suppleness, we narrowed our alternative down to a knowledge lake.
Information lake opens up new prospects for implementing machine learning-based options working on uncooked information for points reminiscent of anomaly detection. It will probably assist information scientists of their day-to-day job. Their pursuit of recent correlations between information coming from completely different sources wouldn’t be attainable in any other case.
That is particularly vital for corporations from the fintech trade, the place each piece of knowledge is urgently essential. However there are many extra industries that would profit from having that means, such because the healthcare trade or on-line occasions trade simply to call just a few.
Let’s check out the information lake on AWS structure
Let’s break the information lake structure down into smaller items. On one aspect, we’ve received numerous information sources. On the opposite aspect, there are numerous BI instruments that make use of the information saved within the heart – the information lake.
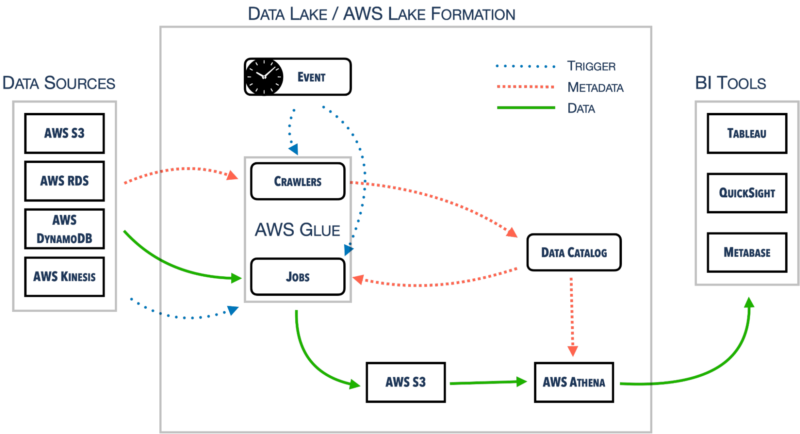
AWS Lake Formation manages the entire configuration concerning permissions administration, information places, and many others. It’s working on the Information Catalog that’s shared throughout different companies as nicely inside one AWS account.
One such service is AWS Glue, liable for crawling information sources and build up the Information Catalog. AWS Glue Jobs makes use of the knowledge to maneuver information round to the S3 and, as soon as once more, replace the Information Catalog.
Final however not least, there’s AWS Athena. It queries S3 instantly. As a way to try this, it requires correct metadata from a Information Catalog. We are able to join AWS Athena to some exterior BI instruments, reminiscent of Tableau, QuickSight, or Metabase with the usage of official or community-based connectors or drivers.
There are extra thrilling cloud implementations ready to be found – like this one wherein we decreased our consumer’s cloud invoice from 30,000$ to 2,000$ a month.
- We decreased the cloud invoice from $30k to $2k a month. If you wish to cut back yours, learn this case examine
Implementing information lake on AWS
The instance structure contains a wide range of AWS companies. That additionally occurs to be the infrastructure supplier of alternative for our consumer.
Let’s begin the implementation by reviewing the choices made accessible to the consumer by AWS.
Information lake and AWS – companies overview
The consumer’s complete infrastructure was within the cloud, so constructing an on-premise answer was not an choice, though that is nonetheless one thing theoretically attainable to do.
At that time utilizing serverless companies was the only option as a result of that gave us a technique to create a proof of idea a lot faster by shifting the duty for the infrastructure onto AWS.
One other nice advantage of that was the truth that we solely wanted to pay for the precise utilization of the companies, extremely lowering the preliminary price.
The variety of companies supplied by AWS is overwhelming. Let’s make it simpler by lowering them to 3 classes solely: storage, analytics, and computing.
Let’s evaluation these we on the very least thought of incorporating into our answer.
Amazon S3
That is the guts of an information lake, a spot the place all of our information, remodeled and untransformed, is situated in. With virtually limitless area and excessive sturdiness (99.999999999% for objects over a given yr), this alternative is a no brainer.
There’s additionally yet one more vital factor that makes it fairly performant within the total answer, which is the scalability of learn and write operations. We are able to arrange every object in Amazon S3 utilizing prefixes. They work as directories in file methods. Every prefix supplies 3500 write and 5500 learn operations per second and there’s no restrict to the variety of prefixes that we are able to use. That actually makes the distinction as soon as we correctly partition our information.
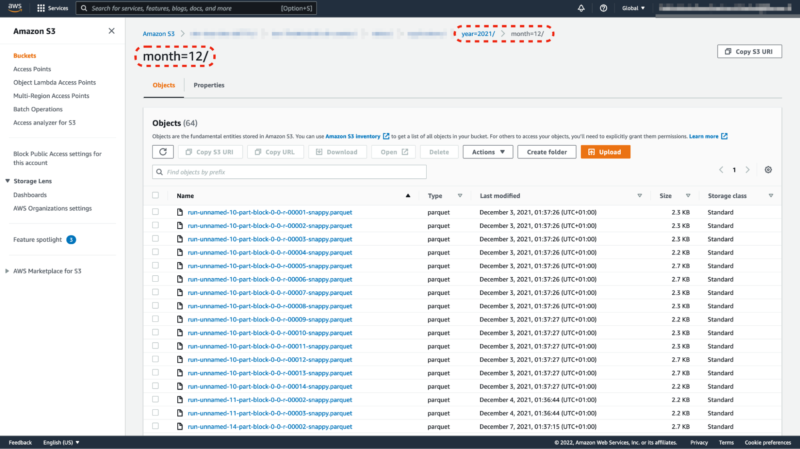
Amazon Athena
We are able to use the service for working queries instantly in opposition to the information saved in S3. As soon as information is cataloged, we are able to run SQL queries and we solely pay for the amount of scanned information, round 5$ per 1TB. Utilizing Apache Parquet column-oriented information file format is likely one of the greatest methods of optimizing the general price of information scanning.
Sadly, Amazon Athena just isn’t an incredible software for visualizing outcomes. It has a slightly easy UI for experimentation but it surely’s not sturdy sufficient to make severe evaluation. Plugging in some sort of exterior software is just about compulsory.
AWS Lake Formation
The purpose of this service is to make it simpler to keep up the information lake. It aggregates functionalities from different analytics companies and provides some extra on prime of them, together with fine-grained permissions administration, information location configuration, administration of metadata, and so forth.
We may definitely create an information lake with out AWS Lake Formation however it will be rather more troublesome.
AWS Glue
We are able to engineer ETL and ELT processes utilizing AWS Glue. It’s liable for an incredible vary of operations reminiscent of:
- information discovery,
- sustaining metadata,
- extractions,
- transformations,
- loading.
AWS Glue presents a number of ready-made options, together with:
- connectors,
- crawlers,
- jobs,
- triggers,
- workflows,
- blueprints.
We’d have to script a few of them. We are able to do it manually or with the usage of visible code turbines in Glue Studio.
Enterprise intelligence instruments
AWS has one BI software to supply, which is Amazon QuickSight. There are a number of alternate options available on the market, reminiscent of Tableau or Metabase. The latter is an attention-grabbing choice as a result of we are able to use it as both a paid cloud service or on-premise with no further licensing price. The one price comes with having to host it on our personal. In any case, it requires an AWS RDS database to run in addition to some Docker containers working a service reminiscent of AWS Fargate.

Amazon Redshift
Amazon Redshift is a superb alternative for hybrid options, together with information warehouses. It’s value it to say that Amazon Redshift Spectrum can question information instantly from Amazon S3 similar to Amazon Athena. This method requires organising an Amazon Redshift cluster first, which could be an extra price to contemplate and consider.
AWS Lambda
Final however not least, some information pipelines can make the most of AWS Lambda as a compute unit that strikes or transforms information. Along with AWS Step Features, it makes it straightforward to create scalable options geared up with features which are nicely organized into workflows.
As a aspect word – are Amazon Athena and AWS Glue a cure-all?
Some devs appear to consider that in terms of information evaluation, Amazon Athena or AWS Glue are practically as omnipotent because the goddess that impressed the previous’s title. The reality is that these companies usually are not reinventing the wheel. In truth, Amazon Athena makes use of Apache Presto and AWS Glue has Apache Spark below the hood.
What makes them particular is that AWS serves them in a serverless mannequin, permitting us to concentrate on enterprise necessities slightly than the infrastructure. To not point out, having no infrastructure to keep up goes a great distance towards lowering prices.
We proved our AWS proves creating a extremely personalized implementation of Amazon Chime for certainly one of our shoppers. Right here’s the Amazon Chime case examine.
- Creating Amazon Chime chat – a mission case examine
Instance implementation – shifting information from AWS RDS to S3
For numerous causes, it will be subsequent to not possible to completely current all the parts of the information lake implementation for this consumer. As an alternative, let’s go over a portion of it so as to perceive the way it behaves in apply.
Let’s take a more in-depth take a look at the answer for shifting information from AWS RDS to S3 by utilizing AWS Glue. This is only one piece of the better answer however exhibits a few of the most attention-grabbing elements of it.
First issues first, we’d like correctly provisioned infrastructure. To take care of such infrastructure, it’s value it to make use of some Infrastructure as Code instruments, together with Terraform or Pulumi. Let’s check out how we may arrange an AWS Glue Job in Pulumi.
It could look overwhelming however that is only a bunch of configurations for the job. In addition to some commonplace inputs reminiscent of a job title, we have to outline a scripting language and an AWS Glue atmosphere model.
Within the arguments part, we are able to cross numerous info that we are able to use in a script to know the place we must always get information from and the place to load it in the long run. That is additionally a spot to allow bookmarking mechanism, which extremely reduces processing time by remembering what was processed in earlier runs.
Final however not least, there’s a configuration for the quantity and sort of staff provisioned to do the job. The extra staff we use, the sooner outcomes we are able to get on account of parallelization. Nevertheless, that comes with the next price.
As soon as now we have an AWS Glue job provisioned, we are able to lastly begin scripting it. One technique to do it’s simply by utilizing scripts auto-generated in AWS Glue Studio. Sadly, such scripts are fairly restricted in capabilities in comparison with manually written ones. Alternatively, the job visualization characteristic makes them fairly readable. All in all, it could be helpful for some much less demanding duties.
This job was rather more demanding. We couldn’t create it in AWS Glue Studio. Subsequently, we determined to put in writing customized scripts in Python. Scala is an efficient different too.
We begin by initializing a job that makes use of Spark and Glue contexts. This as soon as once more reminds us of the actual expertise below the hood. On the finish of the script, we commit what was set in a job and the actual execution solely begins then. As a matter of truth, we use the script for outlining and scheduling that job first.
Subsequent, we iterate over tables in a Information Catalog saved there beforehand by a crawler. For every of the specified tables, we compute the place it needs to be saved later.
As soon as now we have that info, we are able to create a Glue Dynamic Body from a desk in Information Catalog. Glue Dynamic Body is a sort of abstraction that permits us to schedule numerous information transformations. That is additionally a spot the place we are able to arrange job bookmarking particulars such because the column title that’s going for use for that goal. The transformation context can be wanted for bookmarking to make it work correctly.
To have the ability to do further information transformation, it’s obligatory to remodel a Glue Dynamic Body into Spark Information Body. That opens up a chance to counterpoint information with new columns. On this case, these would come with years and months derived from our information supply. We use them for information partitioning in S3, which provides an enormous efficiency increase.
Ultimately, we outline a so-called sink that writes the body. Configuration consists of a path the place information needs to be saved in a given format. There are just a few choices reminiscent of ORC or Parquet, however crucial factor is that these codecs are column-oriented, and optimized for analytical processing. One other set of configurations permits us to create and replace corresponding tables within the Information Catalog routinely. We additionally mark the columns used as partition keys.
The entire course of runs in opposition to a database consisting of a few tens of gigabytes and takes only some minutes. As soon as the information is correctly cataloged, it turns into instantly accessible to be used within the SQL queries in Amazon Athena, due to this fact in BI instruments as nicely.
Deliverables – new information system and its implications
On the finish of the day, our efforts in selecting, designing, and implementing an information lake-based structure offered the consumer with a number of advantages.
Enterprise
- Information scientists may lastly concentrate on exploring information within the firm, as an alternative of attempting to acquire the information first. Based mostly on our calculations, it improved the effectivity of information scientists on the firm by 25 p.c on common.
- That resulted in extra discoveries every day and due to this fact extra intelligent concepts on the place to go as an organization.
- The administration of the corporate had entry to real-time BI dashboards presenting the precise state of the corporate, so essential in environment friendly decision-making. They not wanted to attend fairly a while to have the ability to see the place they had been.
Technical
So far as technical deliverables go, the tangible outcomes of our work embrace:
- structure design on AWS,
- infrastructure as code,
- information migration scripts,
- ready-made pipelines for information processing,
- visualization atmosphere for information analytics.
However the consumer just isn’t the one one which received so much out of this mission.
Don’t sink within the information lake on AWS – get seasoned software program lifeguards
Implementing an information lake on an AWS-based structure taught us so much.
- In terms of information methods, it’s usually a good suggestion to begin small by implementing a single performance with restricted information sources. As soon as we arrange the processes to run easily, we are able to prolong them with new information sources. This method saves time when the preliminary implementation proves flawed.
- In a mission like this, wherein there are a number of uncertainties at first, serverless actually shines by. It permits us to prototype shortly with out having to fret about infrastructure.
- Researching all of the accessible and viable information engineering approaches, platforms and instruments is essential earlier than we get to the precise growth as a result of as soon as our information system is about up, it’s pricey to return. And on daily basis of inefficient information analytics setup prices us within the enterprise intelligence division.
In a world the place traits are being modified so usually, this research-heavy method to growth actually locations us a step forward of the competitors – similar to correctly organising enterprise intelligence itself.
















![[Review] Airbot Robotic Vacuum Mop L108S Pro Ultra features](https://newselfnewlife.com/wp-content/uploads/2024/04/airbot-robotic-vacuum-L108S-pro-ultra-001-120x86.jpg)







{kind=link}